Decoder interface
이전에 Demuxing 작업을 통해서 가져온 packet은 압축된 audio, video data이다. 따라서 실제로 재생을 하기 위해서는 압축을 풀어줄 필요가 있는데, 이를 Decoding이라고 부른다. 따라서 Decoder의 input은 packet (여기서는 AVPacket)이 될 것이며 output은 압축이 풀린 data (여기서는 AVFrame)이 된다. 이에 따라 구현할 Decoder의 interface는 다음과 같다.
decoder.h
class Decoder {
public:
Decoder();
~Decoder();
void init();
bool getFrame(std::shared_ptr<AVPacket> &packet,
std::shared_ptr<AVFrame> &frame);
};
인터페이스의 내용은 앞선 Demuxer와 크게 다르지 않다. 다른 점이라면 getPacket 대신 getFrame함수가 생겼고 기존에 있었던 private 변수가 사라졌다.
한편 Decoder는 압축을 푸는 역할을 하는데 당연하게도 audio data와 video data의 압축을 푸는데는 서로 다른 알고리즘이 사용된다. 즉, audio data를 위한 AudioDecoder, video data를 위한 VideoDecoder를 따로 생성해줘야한다. 알고리즘에 따라 압축을 어떻게 푸는지에 대한 정보는 FFmpeg의 AVCodecContext가 가지고 있다. 이를 위해서 Decoder내부의 private member로 code_context_가 생길 필요가 있다.
decoder.h
class Decoder {
public:
...
private:
std::shared_ptr<AVCodecContext> codec_context_;
};
그런데 codec_context_는 어떻게 초기화 시켜줘야할까? 앞선 내용에서 얘기했었다시피 이미 동영상 컨테이너에서 audio data와 video data의 압축 방식에 대한 정보를 다 포함하고 있다. 그리고 FFmpeg에서 동영상 컨테이너의 메타데이터 정보는 AVFormatContext의 형태로 제공함을 얘기한 바가 있다. 즉 AVFormatContext를 통해 codec_context_를 초기화 할 수 있다!!
하지만 여기서 우리가 video, audio 중 어떤 것에 대한 codec_context_를 만들 것인지에 대한 정보는 따로 입력을 해줘야한다. 이에 대한 정보는 우리가 Demuxer에서 다뤘던 어떤 stream인지에 대한 정보 즉 stream_index를 표현된다. 이에 따라서 Decoder를 생성할 때 AVFormatContext와 stream_index를 넣어준다면 이에 맞는 codec_context_를 생성할 수 있다.
decoder.h
class Decoder {
public:
+ Decoder(int stream_index, std::shared_ptr<AVFormatContext> &fmt_ctx);
- Decoder();
...
private:
+ int stream_index_;
std::shared_ptr<AVCodecContext> codec_context_;
+ std::shared_ptr<AVFormatContext> fmt_ctx_;
}
이제 인터페이스는 얼추 구성이 되었으니 이전의 Demuxer를 이용하여 packet을 받고 이를 Decoder를 통해 AVFrame으로 바꿔주는 test함수를 구현해보자. 앞선 demuxer_test.cc에서 Decoder를 초기화하고 이를 이용하는 부분을 추가해주면 된다.
decoder_test.cc
#include <iostream>
#include "decoder/decoder.h"
#include "demuxer/demuxer.h"
using std::cout;
using std::endl;
using std::make_shared;
using std::shared_ptr;
int main(int argc, char *argv[]) {
av_register_all(); //@NOTE: For FFmpeg version < 4.0
if (argc < 2) {
printf("usage : %s <input>\n", argv[0]);
return 0;
}
std::string file_path = argv[1];
std::shared_ptr<Demuxer> demuxer = make_shared<Demuxer>(file_path);
demuxer->init();
auto video_index = demuxer->getVideoIndex();
auto audio_index = demuxer->getAudioIndex();
auto fmt_ctx = demuxer->getFormatContext();
std::shared_ptr<Decoder> video_decoder =
make_shared<Decoder>(video_index, fmt_ctx);
std::shared_ptr<Decoder> audio_decoder =
make_shared<Decoder>(audio_index, fmt_ctx);
video_decoder->init();
audio_decoder->init();
while (true) {
std::shared_ptr<AVPacket> packet;
demuxer->getPacket(packet);
if (packet.get()) {
if (packet->stream_index == video_decoder->getIndex()) {
std::shared_ptr<AVFrame> frame;
video_decoder->getFrame(packet, frame);
if (frame.get()) {
cout << "Got Video Frame! " << endl;
}
} else if (packet->stream_index == audio_decoder->getIndex()) {
std::shared_ptr<AVFrame> frame;
audio_decoder->getFrame(packet, frame);
if (frame.get()) {
cout << "Got Audio Frame! " << endl;
}
}
} else {
break;
}
}
return 0;
}
여기서 audio packet인지 video packet인지에 따라 video_decoder와 audio_decoder중 맞는 것을 사용해줘야하는데 이를 확인하기 위해서는 packet의 stream_index를 각 decoder의 stream_index와 비교해주어야 한다. 이를 위해 getIndex()라는 함수가 추가되었으며 private변수로 stream_index_가 필요하다.
decoder.h
class Decoder {
public:
...
+ int getIndex() { return stream_index_; }
...
}
이제 마지막으로 decoder.cc를 통해 Decoder구현을 해보자.
decoder.cc
Decoder::Decoder(int stream_index, std::shared_ptr<AVFormatContext> &fmt_ctx)
: stream_index_(stream_index), fmt_ctx_(fmt_ctx), codec_context_() {}
Decoder::~Decoder() {}
void Decoder::init() {
// Do not have to free codec
auto codec = avcodec_find_decoder(
fmt_ctx_->streams[stream_index_]->codecpar->codec_id);
if (codec == NULL) {
cout << "Failed to find video codec" << endl;
}
// Get the codec context
codec_context_ = std::shared_ptr<AVCodecContext>(
avcodec_alloc_context3(codec),
[](AVCodecContext *codec_context) { avcodec_close(codec_context); });
if (!codec_context_.get()) {
cout << "Out of memory" << endl;
}
// Set the parameters of the codec context from the stream
int result = avcodec_parameters_to_context(
codec_context_.get(), fmt_ctx_->streams[stream_index_]->codecpar);
if (result < 0) {
cout << "error : avcodec_paramters_to_context" << endl;
}
if (avcodec_open2(codec_context_.get(), codec, NULL) < 0) {
cout << "error : could not open codec" << endl;
}
}
init과정에서 codec_context_를 초기화하는 과정이 포함되어있다. avcdec_find_decoder를 통해서 codec을 찾고 이를 통해 codec context를 생성한다. 이후 codec_parameter를 codec에 설정해줌으로써 codec_context_ 초기화가 완료된다.
이제 getFrame에 대해서 논의해보자. 사실 getFrame은 다음과 같이 수정이 필요하다. decoder.h
class Decoder {
public:
...
- bool getFrame(std::shared_ptr<AVPacket> &packet,
- std::shared_ptr<AVFrame> &frame);
+ bool getFrame(std::shared_ptr<AVPacket> &packet,
+ std::vector<std::shared_ptr<AVFrame>> &frame_list);
...
}
이런식으로 decoding이 이루어지는 이유는 간단한데, packet을 하나 보낸다고해서 바로 raw data를 가져와지지 않는 경우도 있기 때문이다. 이는 압축방식과 관련이 있는데 정확하지는 않지만 Video를 예시로 들어보겠다.
Video는 연속된 이미지의 집합이라고 볼 수 있다. 달리는 자동차를 찍은 Video를 생각해보자. 다음과 같은 이미지의 연속이 될 것이다.
First 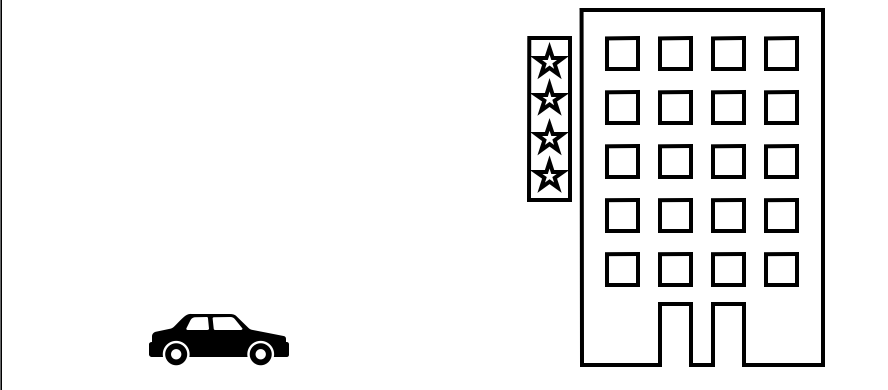 Second
Second 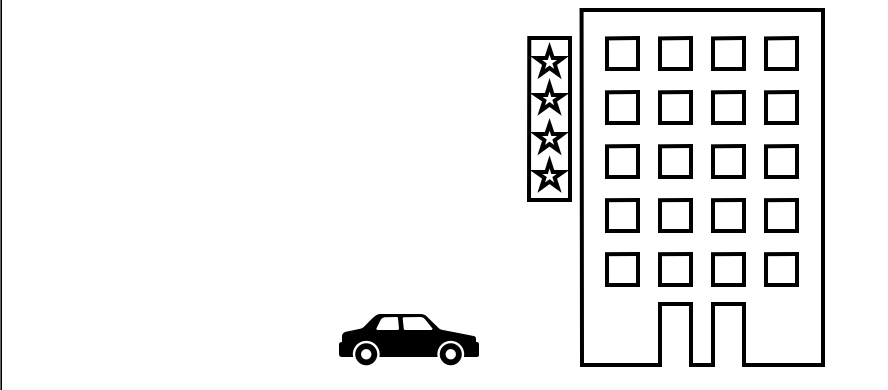 Third
Third 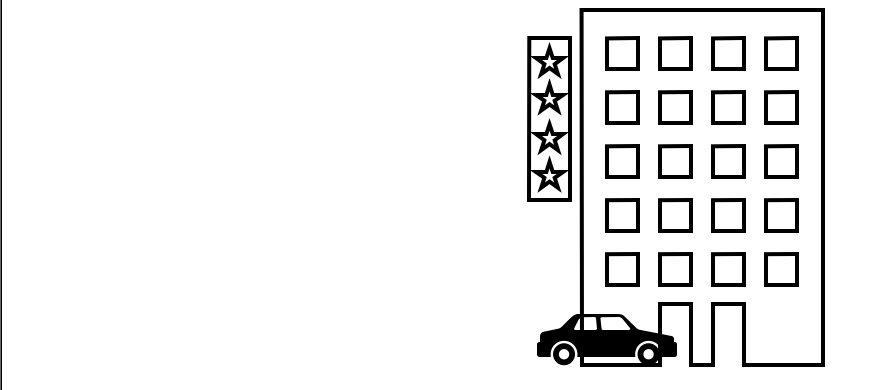 위의 연속된 세 이미지를 봤을 때 빌딩 자체는 움직이지 않는다. 즉 첫번째 이미지를 바탕으로 자동차만 움직이면 두번째 이미지와 세번째 이미지를 만들 수가 있다.
위의 연속된 세 이미지를 봤을 때 빌딩 자체는 움직이지 않는다. 즉 첫번째 이미지를 바탕으로 자동차만 움직이면 두번째 이미지와 세번째 이미지를 만들 수가 있다.
First & Second Image diff 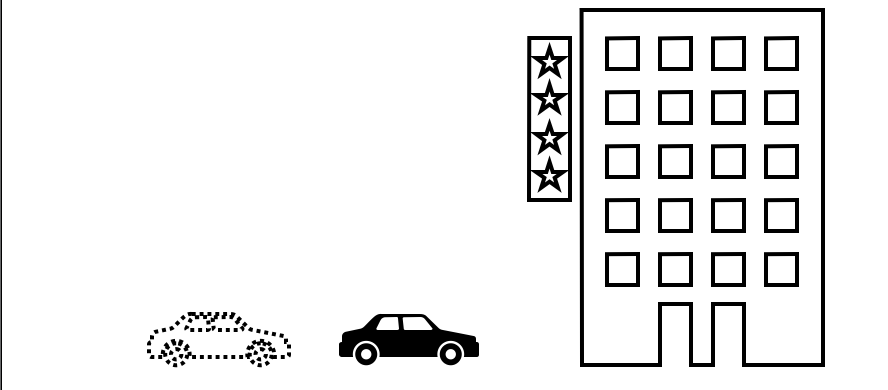 First & Third Image diff
First & Third Image diff 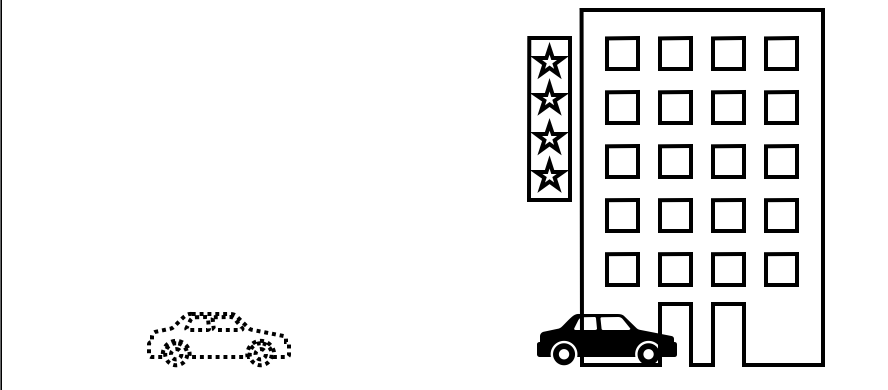
이 경우 압축된 packet은 각각 다음 정보를 가지게 된다
- packet1 : First Image
- packet2 : First & Second Image diff
- packet3 : First & Third Image diff
그리고 packet1, packet2, packet3의 압축을 풀때마다 first image, second image, third image의 순서로 이미지를 얻게 된다.
이외에 First Image와 Thrid Image를 통해 Second Image를 구할 수도 있다. 예시로 만약에 First, Second, Thrid image의 시간 간격이 같다면 Second Image는 First Image에서 Thrid Image에서 자동차가 움직인 만큼의 반만 움직이면 얻을 수가 있다. Second Image from First & Third Image 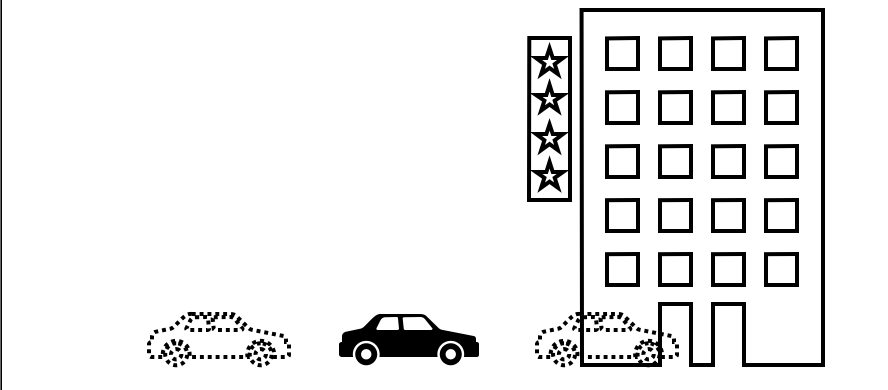
이 경우 압축된 packet은 각각 다음 정보를 가지게 된다
- packet1 : First Image
- packet2 : First & Third Image diff
- packet3 : Second Image from First & Third Image
그러면 packet1, packet2, packet3의 압축을 풀때 first image, third image, second image의 순서로 이미지를 얻게 된다. 즉 packet2의 압축을 풀어도 second image를 구할 수 없게 된다. receive_frame은 시간 순서대로 AVFrame을 반환하기 때문에 packet2를 send 한 순간에는 AVFrame을 얻을 수 없게 된다.
때문에 바뀐 decoder.h에 맞춰 실제 decoder.cc의 구현은 다음과 같다. decoder.cc
...
bool Decoder::getFrame(std::shared_ptr<AVPacket> &packet,
std::vector<std::shared_ptr<AVFrame>> &frame_list) {
frame_list.clear();
auto used = avcodec_send_packet(codec_context_.get(), packet.get());
if (!(used < 0 && used != AVERROR(EAGAIN) && used != AVERROR_EOF)) {
while (true) {
AVFrame *pFrame = av_frame_alloc();
used = avcodec_receive_frame(codec_context_.get(), pFrame);
if (used >= 0) {
frame_list.push_back(
std::shared_ptr<AVFrame>(pFrame, [](AVFrame *pFrame) {
std::cout << "av_frame_free : " << pFrame << std::endl;
av_frame_free(&pFrame);
}));
} else {
av_frame_free(&pFrame);
break;
}
}
}
return true;
}
FFmpeg의 avcodec_send_packet을 통해 packet을 보낼 수 있고 이후 avcodec_receive_frame을 통해서 압축이 풀린 AVFrame을 가져온다. avcodec_receive_frame을 통해 frame을 얻을 때마다 frame_list에 이를 추가한다.
변화된 api에 맞춰 decoder_test.cc도 수정이 필요하다.
decoder_test.cc
...
if (packet->stream_index == video_decoder->getIndex()) {
- std::shared_ptr<AVFrame> frame;
- video_decoder->getFrame(packet, frame);
- if (frame.get()) {
- cout << "Got Video Frame! " << endl;
- }
+ std::vector<std::shared_ptr<AVFrame>> frame_list;
+ video_decoder->getFrame(packet, frame_list);
+ cout << "Video Frame Count : " << frame_list.size() << endl;
+ while (frame_list.size() > 0) {
+ frame_list.erase(frame_list.begin());
+ cout << "Got Video Frame! " << endl;
+ }
} else if (packet->stream_index == audio_decoder->getIndex()) {
- std::shared_ptr<AVFrame> frame;
- audio_decoder->getFrame(packet, frame);
- if (frame.get()) {
- cout << "Got Audio Frame! " << endl;
- }
+ std::vector<std::shared_ptr<AVFrame>> frame_list;
+ audio_decoder->getFrame(packet, frame_list);
+ while (frame_list.size() > 0) {
+ frame_list.erase(frame_list.begin());
+ cout << "Got Audio Frame! " << endl;
+ }
}
} else {
break;
}
}
return 0;
}
이제 Decoder를 통해서 video audio data를 가져올 수 있다!!
다음에는 출력 장치를 통해 재생할 수있도록 data의 형태를 변환시키는 Converter 구현 과정을 써보려고 한다.